Beacon API and why node operators hate it.
Discussing of the main point of pain of the beacon API from the Operator's perspective. Source for all of my claims: https://ethereum.github.io/beacon-APIs

Hello everyone, it has been a while since I made a blog post on my substack. Today, instead of talking about my work on Erigon, I will discuss the pain points and graces of the Beacon API. I will give my feedback and the feedback of node operators I have spoken to about this topic. I will list why node operators/block explorers and chain analysts dislike the API and what can be done to improve it (in my humble opinion). First, let us discuss what is the Beacon API specifically.
What is the Beacon API specifically?

The Beacon API is the interface that allows developers to interact with the Ethereum 2.0 Beacon Chain. It provides developers with access to the necessary tools and functions to build applications, services, and tools on top of the Beacon Chain, enabling them to perform various operations and queries, such as:
Accessing validator information: The API enables developers to access the details of individual validators participating in the network, including their balance, status, and performance.
Managing validators: Developers can use the API to submit validator deposits, initiate validator exits, and perform other validator-related operations.
Beacon chain data: The API provides access to various Beacon Chain data, such as the current epoch, slot, finalized checkpoints, and more.
Monitoring network health: Developers can use the API to monitor the health and performance of the Ethereum 2.0 network, such as tracking validator participation rates, finalization rates, and other metrics.
Submitting attestations and proposing blocks: Validators can use the Beacon API to submit attestations and propose new blocks, fulfilling their roles in the PoS consensus process.
Why is it hated so much by node operators?
Now that we get that out of the way, why is it that it is that so many node operators dislike it? Simply put, it is not powerful enough and can only efficiently satisfy very few use cases. Such use cases are basic validator information retrieval and configuration retrieval; in these specific cases, it has all it needs. However, that is not enough for a large chunk of people and a majority of use cases; below are the major pain points that the Beacon API suffer from (not in order of importance):
Blocks being served are full of useless data that is rarely used with no way of restricting its verbosity.
Querying any state information aside from basic validator data implies querying the entire Beacon state, which is around 122 MB(half a GB in JSON format) in a single query.
There is no indexing being made, which forces block explorers and node operators to build their indexing to give it any meaningful use whatsoever.
Now let us tackle these 3 points together why it is the way it is and how the API can be improved.
Blocks being served are full of useless data that is rarely used with no way of restricting its verbosity.
Let us start with block retrieval, so each Beacon block is composed by its metadata and a series of operations that the validator decided to include, such as slashings, attestations, etc.… In its fashion, it has a header (Slot, Parent root, etc..) and a Body (Slashings, Exits, etc…). In total, one of these queries is sized at ~160KB (json format) per block, which is a non-negligible amount if you consider the use case of node provider and explorer; those 100KB probably cost them a lot of money since this is probably the most used API, and most of the information provided by the query is rarely ever used the two things that take the most space in the query are: Attestations and the Ethereum 1 Block. Attestations take ~70 KB (JSON format), and the EL Block takes ~80 KB, and there is no way to regulate the verbosity (for example, you are forced to receive the whole transaction list of the Ethereum 1 Block which is most of the load).
Problem with the Attestation field
The problem with including full Attestations in a block is that attestations are useless for 99% of use cases. For reference, an Attestation is a statement made by a validator that serves as a vote on the state of the blockchain; the thing about these votes is that there is almost no use other than just verifying their correctness. Not only that, but they are opaque; if you want to see all the attesting indices for an attestation, you would have to produce an index attestation which implies downloading the who Beacon State (122 MB, more if it is a JSON), shuffle the validator set, which is a very CPU intensive operation and after that, you can remove opacity of the Aggregation bits field and see who are the attesting indices for that specific attestation. In any case, most people will not need this field anyway due to its opacity. However, I do believe that it could be helpful in some scenarios where you want to do some kind of chain analysis, personally, I would be fine if Attestations are committed(or reduced) by default from the query and enabled by a flag in case they are needed.
Problem with the Ethereum 1 block
Having the Ethereum 1 Block in the Ethereum 2 Block makes sense, for the sake of convenience, nothing to say. But again, there needs to be a way to reduce the verbosity of transactions. This is a feature that is already present in Execution Layers so I do not see why it should not be the case in Consensus Layers.
Querying any state information aside from really basic validator data implies querying the entire Beacon state which is around 122 MB(half a GB in json format) in a single query.
Currently, we can retrieve Beacon State’s informations in two ways:
Retrieving the whole Historical State
Use dedicated API for a specific state field
If for what you look there is already a dedicated endpoint, then you are good. you wont feel pain. If it does not, then you feel pain.
Why do you feel pain? Because now in order to get that specific information you have to query 122 MB of data. Below you can see which ones have a dedicated field, and which ones do not.
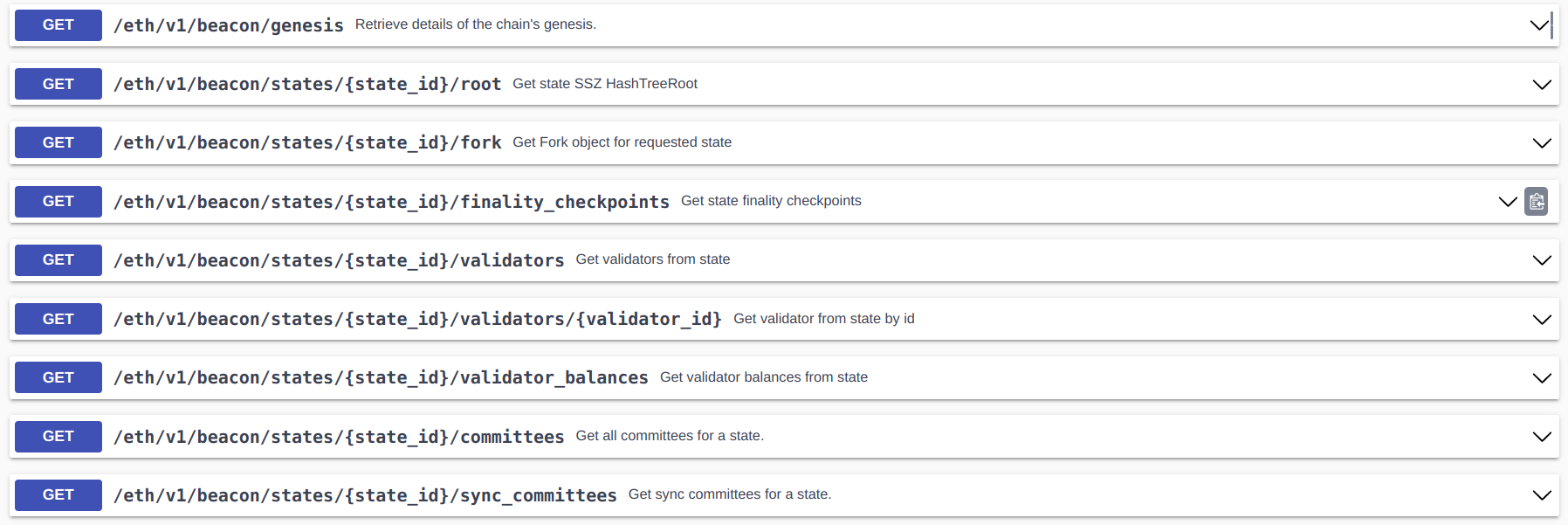
In total 13 of the 27 state fields have dedicated APIs, namely sync committees, basic validator data and checkpoints + configuration of the chain. However, if you dare to ask for other information such as inactivity scores, any shangai-related fields and other stuff, buckle up because the procedure is: 1) Download 122 Megabyte worth of state (500 MB if in Json and not SSZ), 2) Extract 0.001% of that data to do what you need. On top of my head, I can see how inactivity scores and participation bits would be helpful to track validator performance over epochs for example. And if that is your use case, then for every block, you got to download 122 MB every single time (Note: that is 122 MB every 12 seconds). I heard a lot of complaints about this one. Naively, The solution, in this case, could be to add dedicated APIs for each field. On top of this, the API to retrieve state is under the Debug namespace, and funnily enough, I know people who use it in production.
Little indexing forces block explorers and node operators to build their indexing to give it any meaningful use.
Regarding indexing, the Beacon API only indexes data by State Root/Slot/Block Root; no other indexing is being made. Now let's consider a very common case, getting every block/attestation proposed by a validator. What are the steps to accomplish this? There aren't, because you cannot do it. You also do not know which EL block hash is equivalent to which Beacon block and you also cannot track validators’ balance, status, etc.. at all. The thing that needs to be understood here is that without indexing, right now, the Beacon API is useless. You must build a whole daemon on top of it to make it work in meaningful use cases. In terms of a solution, This is a complicated problem but still a real one, and I do not have a straight answer; I will figure it out. Probably the solution is somewhere along the lines of building a low-level APIs and constructing a custom higher-level APIs on top of them.
This is all from me today. Cheers.