6/01/2023: Thoughts about Consensus Layer Re-Archittecturing, current state of the art and Erigon custom EL<->CL communication protocol.
Happy New Year!

Hello Everyone, This is Giulio, I welcome you to yet another one of my rants… This is the first post of the Year and I will be describing all the stuff I did in the past 1 week and a half which I did not document. Also this is probably one of the few post that will go somewhat technical 😱😱😱 as I will explain how I envision Erigon’s own version of the “Engine” API. This new API is currently working as a prototype and PoC and can stay in Sync on Mainnet and Goerli without problems… Also there is a realistic database footprint for a Minimal Consensus node.
Erigon Execution Module API vs Engine API
So let us start by briefly describing what the Engine API is as described by the execution specifications. The Engine API is the interface unit that the Execution Layer serves to the Consensus Layer and is composed by the following RPC Calls:
NewPayload: Validate Execution Data and Insert it in the Execution Layer Database.
ForkChoiceUpdated: Set new chain head to a certain hash and if specified build a new block on top of it.
GetPayload: Retrieve block built with previously called Fcu.
ExchangeTransitionConfiguration: Sanity checks (not important overall, will skip it)
Now, this is probably a good communication protocol overall but it is easy to see how it is conceptually flawed, for example NewPayload do too much stuff, it validates and insert a new block even though these two functionalities should be conceptually separated. ForkChoiceUpdated has the same issue but to a greater extent because not only it does too much stuff but the functionality of building a new block has nothing to do with setting the new chain head, so other than being too bloated, its naming is not very good. Lastly, ForkChoiceUpdated + GetPayload just sounds very wrong and is just weird in naming. These are really some superficial critics that I would make, However, in most cases, I would argue that this API is misused by Consensus Layers and is overall not very flexible. Now let me explain why…
Engine API(Con): Misused.
Let me start with how it is misused, basically to a conceptual level, every time a Consensus Layer receives a new Beacon block it is supposed to call ForkChoiceUpdated on its Payload so that it sets the new head and plus it needs to do prior validation. And this sounds good on paper but it makes no sense in practice. Here is why: If the Consensus Layer is catching up because of whatever reason,it will get new blocks, send a NewPayloads then set the ForkChoice for each of these blocks. now this will make most Execution Layer process blocks one by one which is slow as it can lead to catch up sync up to 6 hours(it happened to me once) for just a week worth of being disconnected, because unbatched replaying of transactions is usually very slow. Now you may wonder that perhaps this is necessary but it is not. That is because Consensus Layers can estimate very well when we are close to the chain tip by using plain unix time. As a matter of fact, Ethereum R&D came up with Optimistic Sync, which is a solution but far from being a good solution due to the fact that it leads to loss of Execution Payloads data in the process, since the Execution cannot receive NewPayload calls, because as I want to remind to everyone NewPayload consists of slow Validation + Actual insertion. And here kind of come the issue of flexibility, but we will get more in-depth later about that aspects. The solution is to only call ForkChoiceUpdated only at the tip of the chain (determined by the unix clock) and somehow have NewPayloads not perform validation. The former is possible the latter is not unfortunately. Lastly, The combination of NewPayload + ForkchoiceUpdated is probably not what I would want Consensus Layer to do most of the time anyway.
Engine API(Con): Lack of flexibility.
Now let us talk about its lack of flexibility. As I mentioned before, NewPayload is not flexible because it does not allow straight insertion without validation. this is important because if it would be possible to just have an Insert for Headers/Block bodies then the communication between these two components could be more optimized and also easier to handle. Secondly, it makes no sense to me to have ForkchoiceUpdated complete the task of building a block unless you want to build on two different side forks, and even in that case, it is a waste of computation, since you can just add an optional parameter to a possible assembleBlock function. If the parameter is set, simulate the side fork and build the block on the simulation, get the same result with half the bloat, and with much faster block building as switching ForkChoice is computationally intensive since it writes to the Execution Database. Lastly, but more importantly, the Engine API is Asynchronous which is a useless feature most of the time (at least in my opinion), in the sense that if a Forkchoice or a NewPayload is not ready in time, the Execution layer and Consensus Layer cannot validate, Asynchronous or not. Synchronicity just makes us work with better assumptions on what is going on, at least in this case. Conceptually Consensus Layers depends externally on Execution Layers so Asynchronous calls are not of much use than to just sync a couple of blocks while the Execution Layer is busy.
Engine API(Con): Network Bloat.
This is my favorite one, THE NETWORK BLOAT. Basically, with The Merge we have now 2 Ethereum networks: the Beacon Network and the Execution Network, with the Execution Network now being a subset of the Beacon Network. It makes no sense to have 2 different networks that sends over the same data. It is just a waste of bandwidth, also this distinction causes node operator to store Post-Merge execution blocks history twice: once in the Execution Layer and once in the consensus Layer. If you run only the Beacon Network and extract EL data and use it as the networking layer then it should be better.
Engine API(Con): Not modular.
The Engine API only accounts for Ethereum 2, it would not work for BSC/Polygon and other Consensus Algos. It is not modular, it is Ethereum centric. And no, for most of the above consensus Algos you would need to really restructure the Engine API in order to achieve a proper implementation and not create a mess.
Engine API(Pro): Compatibility.
The Engine API allows us to be compatible with all other Consensus Layers, however, we probably will drop such compatibility in the future anyway because interoperability is a pain, and the Consensus Layer is basically half Execution Layer with some modifications and different state transition so It is not that much of a gigantic job to maintain it within Erigon. I guess it is just a different set of priorities.
What did I come up with for Erigon.
I built a working prototype of a communication protocol beetwen Execution Layer and Erigon Consensus Layer that makes it so that:
Erigon Execution Layer NEVER downloads blocks itself (pre-bellatrix blocks are in our bittorent history snapshots anyway). Erigon literally do not have the P2P service connected to its own StageLoop so it does not even connect to the P2P network, except for the transaction pool.
There is no history repetition.
Retrieval of Execution data is fast thanks to gRPC, and because it is a direct query to Erigon database.
Validation of new blocks (outside of Forkchoice) happens strictly near chain tip.
Forkchoice happens ONLY at chain tip.
Lastly this is how this new communication protocol looks like on functional level:
InsertBodies: Batched insertion in Erigon-EL of transactions/withdraws/uncles (no validation).
InsertHeaders: Batched insertion in Erigon-EL of execution Headers (no validation).
UpdateForkChoice: Set new chain tip without option of assembling payload.
AssemblePayload: Creates new payload on top of forkchoice.
GetBody: Fast query of block body.
GetHeader: Fast query of block header.
IsCanonical: Whether the ETH1 hash is canonical.
HeaderNumber: returns block number given the hash.
What is happening is that:
we perform BackFilling until either we download the full history(if we want to) or whenever we encounter a reconnection point with the Execution Layer in the Beacon network.
We Insert all Execution Payloads with InsertHeaders + InsertBodies in batches (we send multiples per gRPC call).
Download missing blocks forward and do the same batched insertions we did in step 2.
Apply state transition (not yet present) CL-side and ONLY at the end call ForkChoiceUpdated on the last beacon block.
You can check all of this in the Erigon codebase if you want. The PoC I made can sync Goerli and Mainnet. The interesting thing is that in this Archittecture the EL is completely passive and it is just a database as it does nothing on its own.
Realistic Erigon-CL disk footprint with Minimal storage.
In order to just run a Beacon node with validation you need only: latest 500k blocks, 2 Beacon States, Indexing. where 500k blocks is approximately the weak subjectivity limit. Here is what it looks like with a DB footprint of of 6.2 GB completely uncompressed:
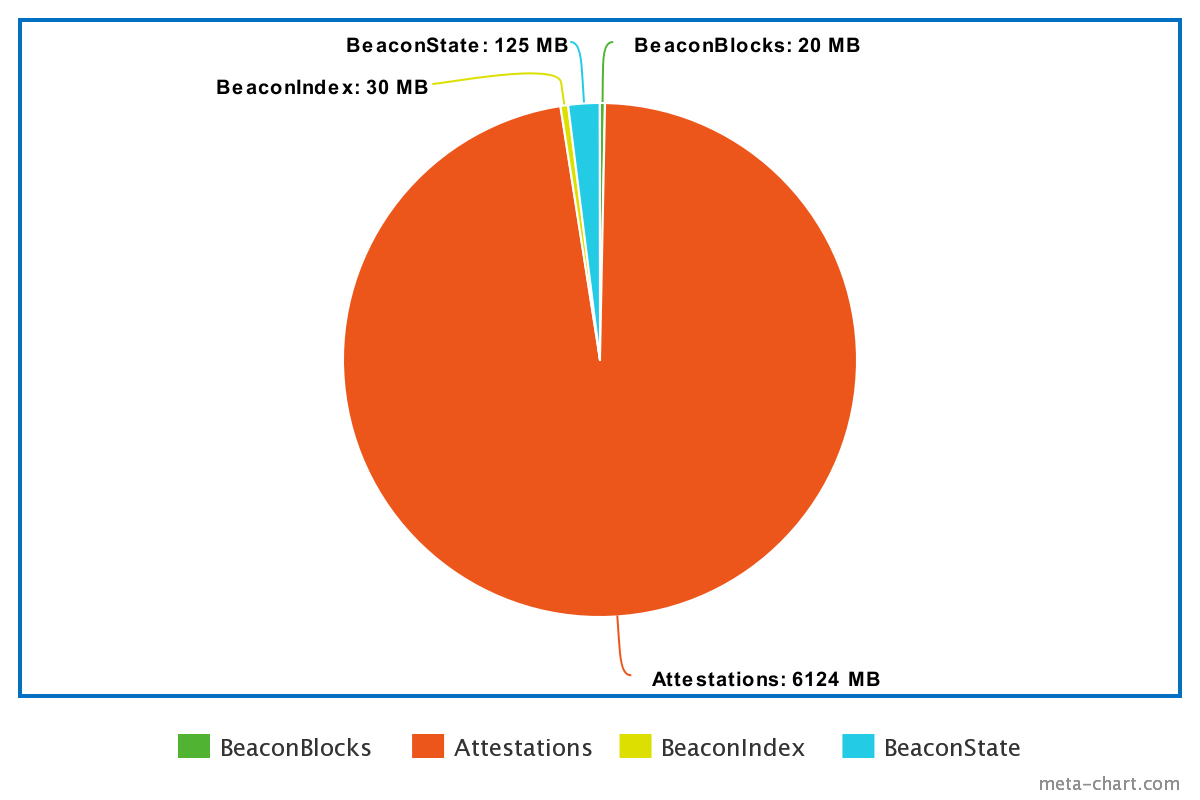
This will allow Erigon-CL instances for validators to be super lightweight in order to account for cheap hardware.
Hope you liked the article.
Fin.